Code
length(list.files("data_ocr", pattern = "\\.txt$", full.names = TRUE))[1] 20
Я собрала небольшой корпус текстов на европейском языке (английский): 20 одностраничных PDF-документов.
Дальше я сделала пайплайн: OCR → очистка → лемматизация и частоты → коллокации и визуализация → отчёт в Quarto.
Папки проекта:
data_raw/ — исходные PDFdata_ocr/ — результат OCR (.txt)data_clean/ — очищенные тексты (.txt)outputs/tables/ — таблицы со статистикойoutputs/figures/ — картинки (графики/сеть)R/ — скрипты пайплайнаДля каждого PDF я делала так:
tesseract.На выходе получилось 20 файлов в data_ocr/.
length(list.files("data_ocr", pattern = "\\.txt$", full.names = TRUE))[1] 20После OCR в тексте обычно есть мусор: странные переносы, лишние пробелы, артефакты форматирования. Я почистила это регулярными выражениями, чтобы потом нормально считать статистику.
Что делала (основные правила):
\\r\\n → \\n)exam-\\nple → examplef_raw <- list.files("data_ocr", pattern="\\.txt$", full.names=TRUE)[1]
f_clean <- file.path("data_clean", basename(f_raw))
cat("=== ДО ОЧИСТКИ (OCR) ===\n")=== ДО ОЧИСТКИ (OCR) ===cat(paste(readLines(f_raw, warn=FALSE)[1:10], collapse="\n"))2. What is Culture?
I sit with several students in a café in Paris.
We have an international meeting. Americans, French, and Germans sit at
a table and discuss.
The American asks, "What does culture mean in this country?"
I say, "That term can mean a lot. Literature, theatre, art, or even the way we
speak, including the way you conduct yourself."
"Does it also include behavior? " asks the American.
"Behavior in general terms, probably is a part of it," says the German.
"So that means when I behave I have culture," ask the American smiling.cat("\n\n=== ПОСЛЕ ОЧИСТКИ (clean) ===\n")
=== ПОСЛЕ ОЧИСТКИ (clean) ===cat(paste(readLines(f_clean, warn=FALSE)[1:10], collapse="\n"))2. What is Culture?
I sit with several students in a café in Paris.
We have an international meeting. Americans, French, and Germans sit at
a table and discuss.
The American asks, "What does culture mean in this country?"
I say, "That term can mean a lot. Literature, theatre, art, or even the way we
speak, including the way you conduct yourself."
"Does it also include behavior? " asks the American.
"Behavior in general terms, probably is a part of it," says the German.
"So that means when I behave I have culture," ask the American smiling.Очищенные тексты я разметила через udpipe (модель: english-ewt). Потом я сделала частотный словарь по леммам.
Леммы мне нужны, потому что одно и то же слово может быть в разных формах, и так проще считать.
library(readr)
lemma_path <- "outputs/tables/lemma_freq_top50.csv"
if (!file.exists(lemma_path)) {
stop("Не найден файл: ", lemma_path, "\nПроверь, что пайплайн создал outputs/tables/lemma_freq_top50.csv")
}
lemma_top50 <- read_csv(lemma_path, show_col_types = FALSE)
lemma_top50# A tibble: 50 × 2
lemma n
<chr> <dbl>
1 the 174
2 be 138
3 a 111
4 and 100
5 to 81
6 i 76
7 in 59
8 we 59
9 have 48
10 of 48
# ℹ 40 more rowsФайлы шага:
outputs/tables/udpipe_tokens.csvoutputs/tables/lemma_freq_total.csvoutputs/tables/lemma_freq_top50.csvДальше я искала коллокации (устойчивые сочетания). Я брала биграммы (соседние леммы внутри предложения) и считала PMI.
PMI показывает, насколько пара слов встречается вместе чаще, чем “случайно”.
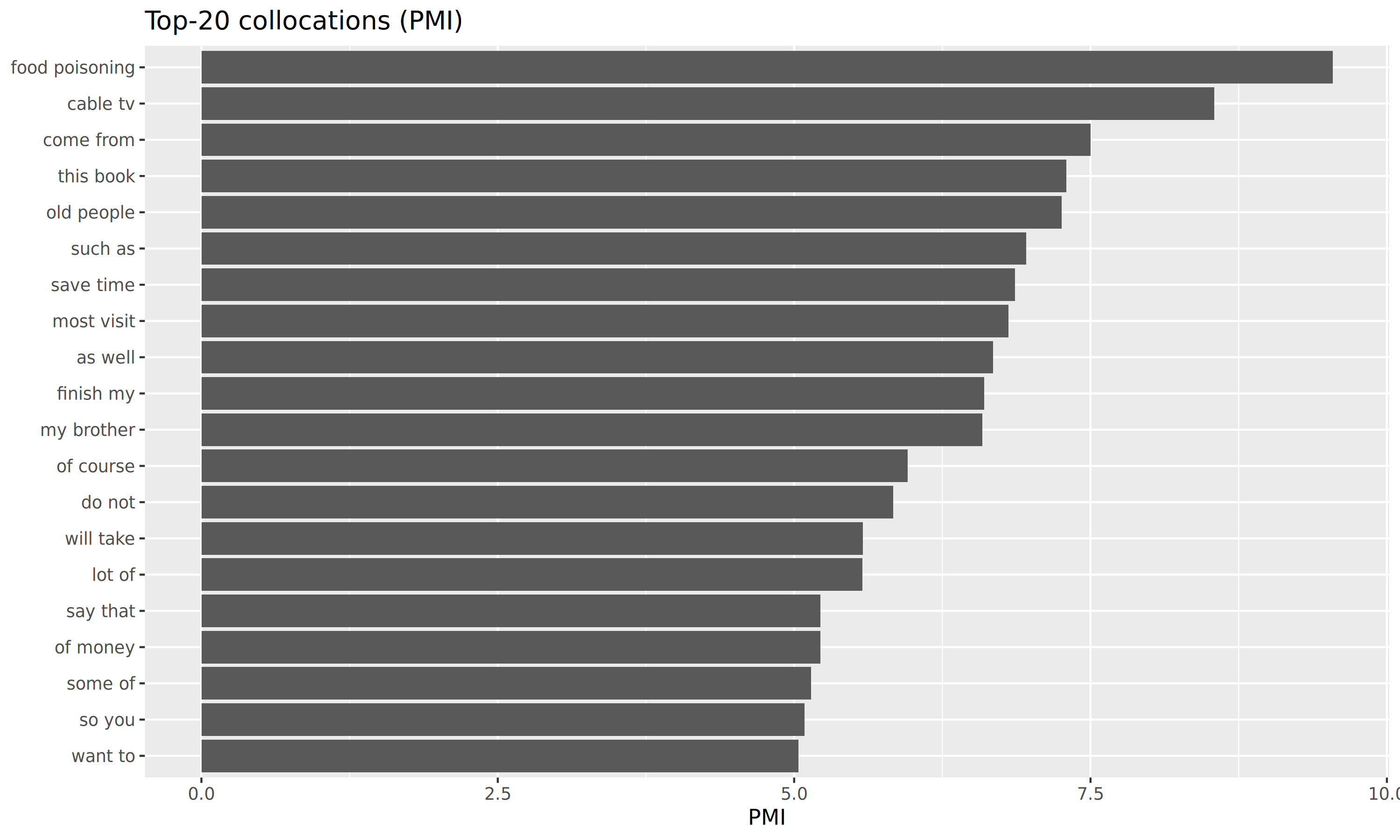
В топе получились нормальные пары (типа “food poisoning”, “cable tv”, “old people”), а ещё частые связки вроде “of course”, “do not”, “such as”.

Сеть просто помогает посмотреть, какие слова часто “цепляются” друг за друга и образуют группы.
Полная таблица коллокаций:
library(dplyr)
Attaching package: 'dplyr'The following objects are masked from 'package:stats':
filter, lagThe following objects are masked from 'package:base':
intersect, setdiff, setequal, unionlibrary(readr)
coll_path <- "outputs/tables/collocations_pmi.csv"
if (!file.exists(coll_path)) {
stop("Не найден файл: ", coll_path, "\nПроверь, что пайплайн создал outputs/tables/collocations_pmi.csv")
}
coll <- read_csv(coll_path, show_col_types = FALSE)
coll %>% head(10)# A tibble: 10 × 6
w1 w2 n n1 n2 pmi
<chr> <chr> <dbl> <dbl> <dbl> <dbl>
1 food poisoning 3 4 3 9.54
2 cable tv 3 4 6 8.54
3 come from 4 6 11 7.50
4 this book 4 19 4 7.30
5 old people 6 9 13 7.26
6 such as 3 3 24 6.96
7 save time 3 7 11 6.86
8 most visit 3 16 5 6.81
9 as well 6 25 7 6.68
10 finish my 3 4 23 6.60